APIs
application programming interfaces (APIs)
The Marine Sensitivity Toolkit (MST) is a stack of software components for reproducibly, interactively and hierarchically generating environmental vulnerability maps and scores. Tabular data is collated across studies evaluating sensitivity of species to oil & gas and offshore wind energy development. The best available species and benthic habitat distributions are being mosaicked across the US EEZ. Scores are summarized according to subgroups within Species, Benthic Habitats and Primary Productivity, averaged into an overall score, and visualized as a flower plot, applicable to various levels of BOEM relevancy: regional, ecoregions, protraction diagrams, blocks and aliquots.
The software components for achieving this interactively are:
plumber API for data requests and a custom TiTiler factory that renders on-the-fly raster PNG tiles from arbitrary DuckDB queries, cached by Varnish;msens R package, including the tile-URL helpers (cell_tile_url(), cell_stats(), add_cell_tiles()) that the Shiny apps use to talk to the factory;scores, species, …) that combine the raster tile factory with static PMTiles vector layers and live-pushed choropleth paint rules;This toolbox is intended to primarily serve BOEM needs internally, but by being open-source and fully reproducible the hope is to enlist buy-in and even contributions from external partners, whether from other government agencies, academia, NGOs or industry.
We ascribe to the philosophy of sharing all code for the sake of reproducibility, transparency and efficiency (Maitner et al. 2024; Lowndes et al. 2017); i.e. the FAIR principles of Findability, Accessibility, Interoperability, and Reusability (Wilkinson et al. 2016).
We have developed a series of interactive applications to explore the data and results of the MST project. These applications allow users to visualize the data, explore the results, and interact with the data in a more intuitive way. The applications are built using the shiny package in R (Chang et al. 2024), which allows us to easily create a user interface with complex reactivity for an interactive web application easily accessed through a web browser. The applications are designed to be user-friendly and intuitive, with interactive maps, charts, and tables that allow users to explore the data in a more dynamic way.
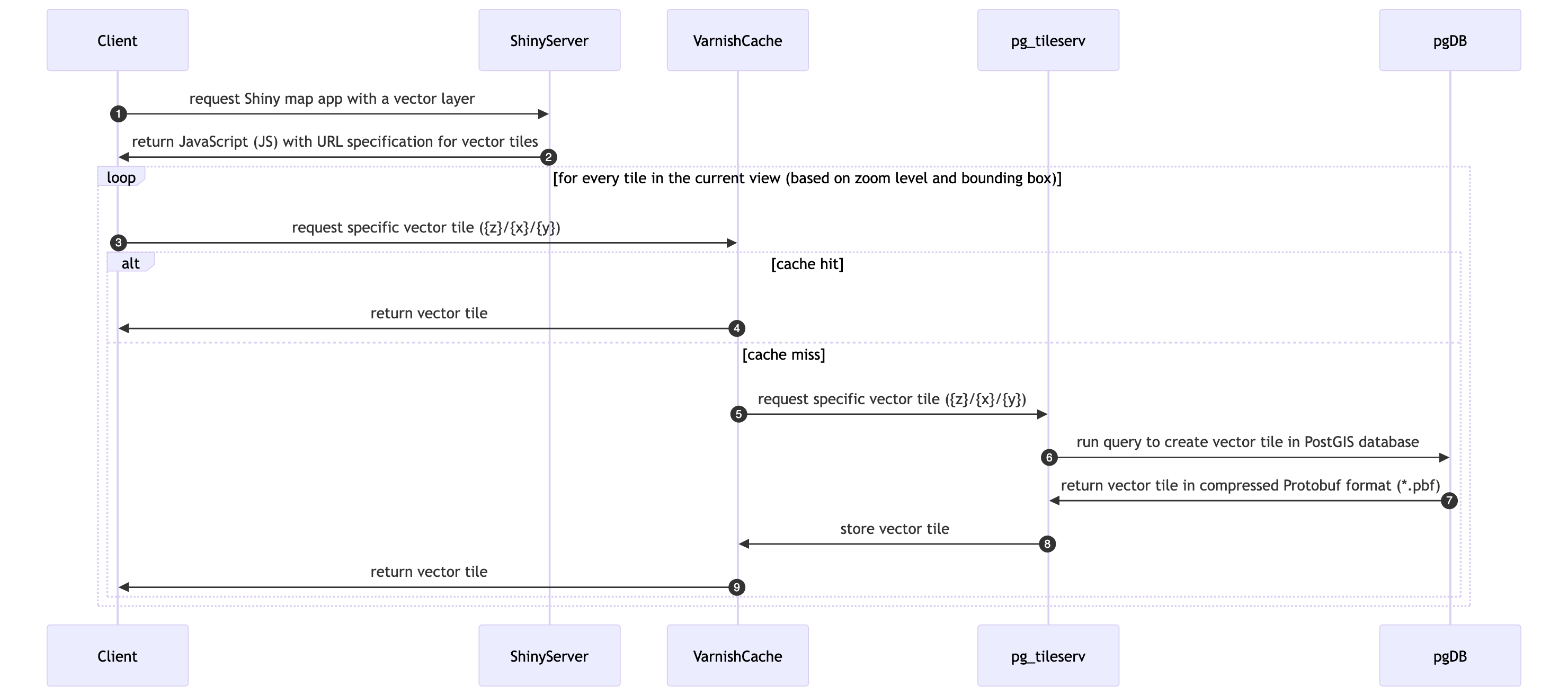
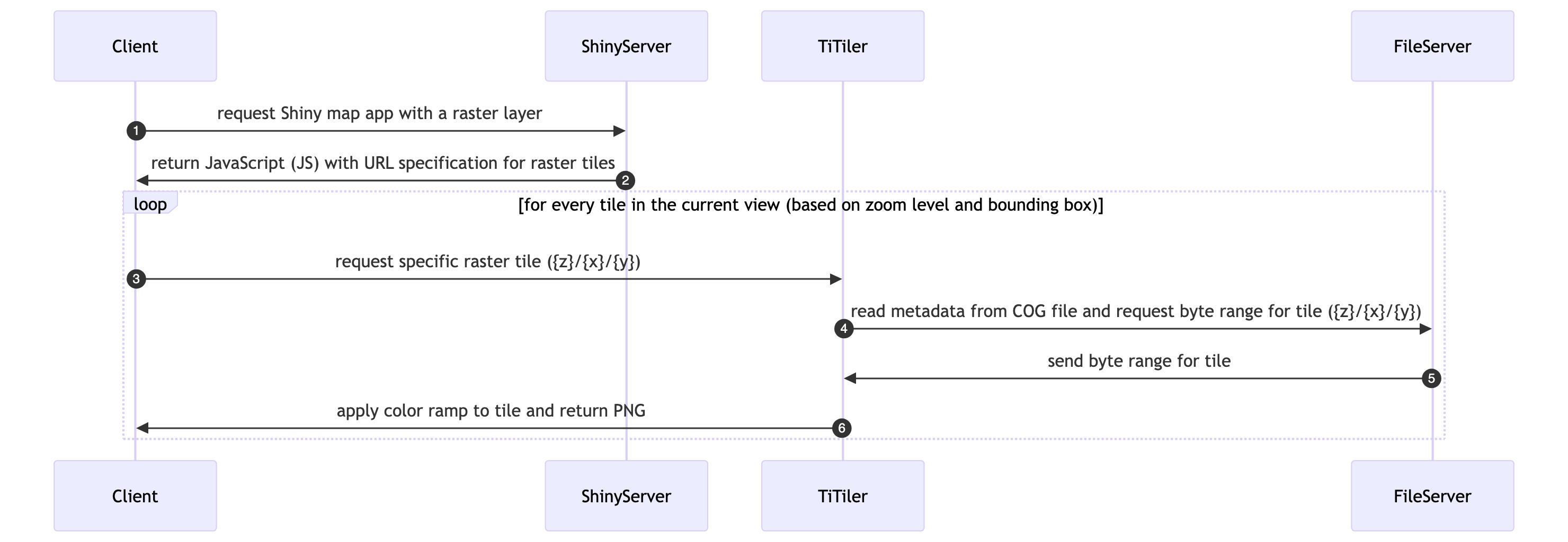
The MST project incorporates many large spatial datasets that are problematic to render in a typical interactive application. For instance, the most common interactive mapping R package leaflet has a 4 MB limitation for displaying rasters (see “Large Raster Warning” in Raster Images • leaflet). Vectors (points, lines and polygons) get smoothed when containing many vertices, but contiguity between polygons is lost and rendering degrades depending on the user’s connection speed.
To work around these limitations we use a “cloud native” stack (see also the Cloud-Optimized Geospatial Formats Guide) that transfers only the pixels / features visible in the current viewport:
256×256 PNG tiles.mapbox-gl match expression, so geometry stays static but color updates as the user changes metric / subregion.Let’s take a closer look at each.
Each metric (e.g., extrisk_mammal) resolves, in DuckDB’s cell_metric table, to a list of (cell_id, value) rows — one row per 0.05°-resolution grid cell in the US EEZ. To show these in the browser we would historically have to materialize the full raster (∼4 GiB for the whole EEZ) and ship it over the wire.
Instead we keep the values in DuckDB and extract only the tiles the user’s browser is asking for. The Shiny app builds a small SELECT, base64-encodes it and embeds it in the tile URL template. On tile request, our custom TiTiler factory:
sqlglot) and executes it once per unique query, LRU-caching the resulting cell_id → value map in-process;r_cellid.tif) via nearest-neighbor resampling, so integer ids are never interpolated;Varnish sits in front of the factory and caches each tile URL for 7 days, so once a tile has been rendered for a given SQL + colormap + rescale combination, every subsequent viewer is served from cache in sub-millisecond time (Figure 10.2). A mtime query parameter tied to the source DuckDB’s modification time automatically busts the cache when the DB is rebuilt.
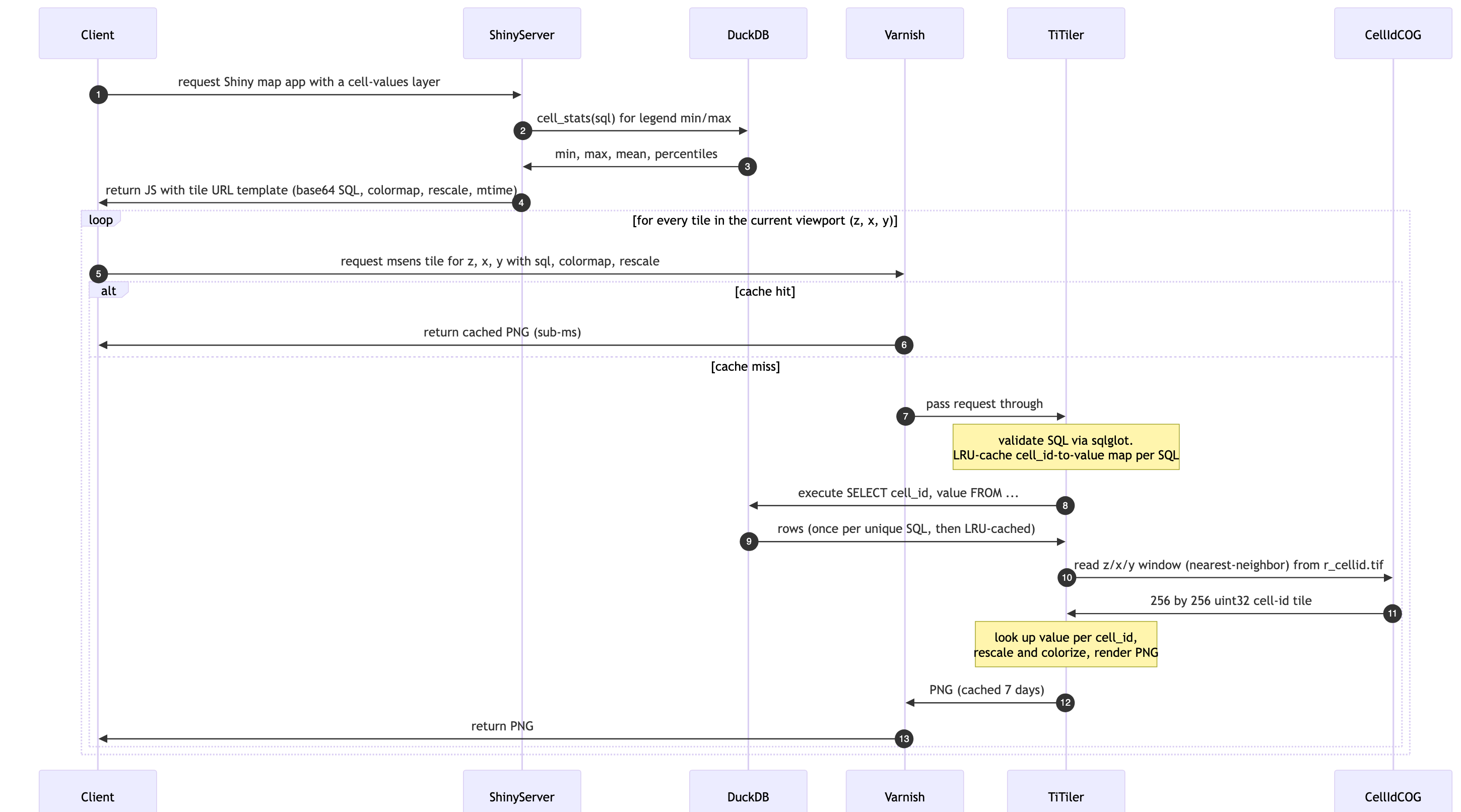
The same factory also supports a single-color “mask” render — the “Cells outside Program Areas” overlay in mapgl is built this way: a SQL that returns all cells with metric data not in any Program Area zone, rendered with color=#222222 (no colormap, no rescale) as a semi-transparent dark overlay.
For polygon layers (Program Areas, Ecoregions, Planning Areas, protractions, blocks, aliquots) we build PMTiles archives offline via tippecanoe and publish them as static files on the server. A PMTiles archive is a single file with an internal directory structure that lets any HTTP client issue small range requests for individual tiles; no tile server process is required — Caddy’s static file handler is all we need (Figure 10.3).
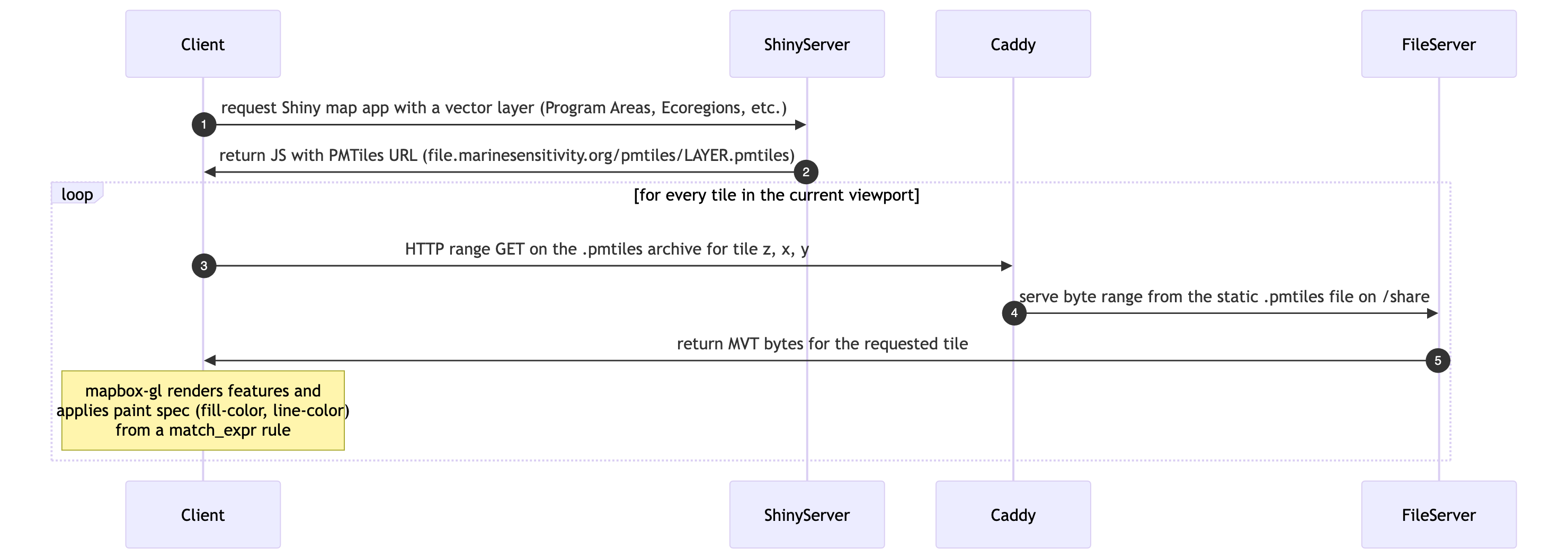
This is a deliberate simplification from the prior architecture which used PostgreSQL + PostGIS + pg_tileserv. For our workload — polygon layers that change only when the data is rebuilt — a compiled tile server and live database query engine add latency and operational complexity for no benefit over byte-range reads of a pre-baked archive. (The PostgreSQL service remains in docker-compose.yml for compatibility with a few legacy apps; see Chapter 11.)
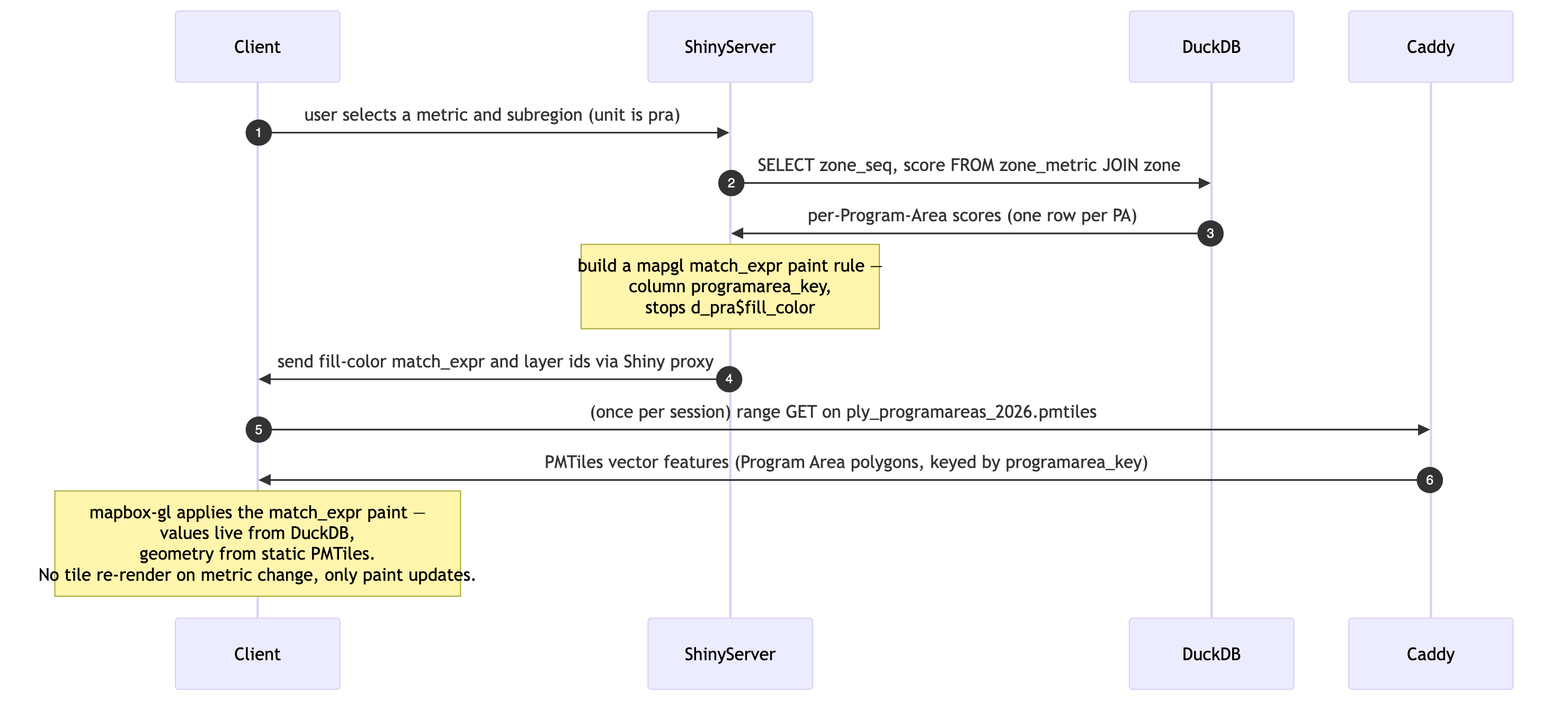
The Program Area choropleth is the interesting hybrid case. The geometry (Program Area polygons keyed by programarea_key) is static — it comes from the same PMTiles file as the polygon outlines. But the fill color depends on the currently-selected metric + subregion, which means the per-Program-Area score has to come live from DuckDB.
The Shiny server handles this by querying zone_metric (pre-aggregated per-zone values), building a mapbox-gl match expression that maps programarea_key → fill_color, and pushing that paint rule to the map through mapgl’s Shiny proxy. No tiles are re-rendered; only the paint specification changes (Figure 10.4).
The three serving paths above all sit downstream of the same data pipeline: ingest workflows populate DuckDB from ∼7 source datasets (AquaMaps, IUCN, NMFS/FWS, BirdLife, WoRMS/eBird taxa, BOEM zones, …); calc_scores.qmd computes per-cell and per-zone metrics back into DuckDB; and a one-shot make_cellid_cog.py bakes the cell-id COG consumed by the TiTiler factory. PMTiles archives are built offline from the same zone geopackages used to populate the zone table (Figure 10.5).